Click to enlargeDescription:Automatically Separate Tiff images or Searchable PDFs by their Text Content
OCR File Splitter is a program that is designed to split files based upon text contents. It can be used on Tiff Images (requires Microsoft Office Document Imaging) or searchable PDF files.
The program will separate a multi-page file into individual files by applying rules to each page of the document. If text is present that matches a rule it will become the first page of a new document, if it is not present the page will be added to the previous document.
With this logic files can be mixed together as the first page on one document may contain "Acme Corp" and on another it may contain "Consolidated Corp" etc., as the program can process an unlimited amount of rules when searching for the first page of a document.
The program monitors (watches) file folders for images to process. As many folders as desired can be watched with each having a different set of rules being applied to the files. This allows an easier setup if in the workflow process some manual separation can be done. For instance, the program could be used to separate all Invoices and purchase orders in one batch; however, if purchase orders and invoices were both placed in separate input folders setup would be easier.
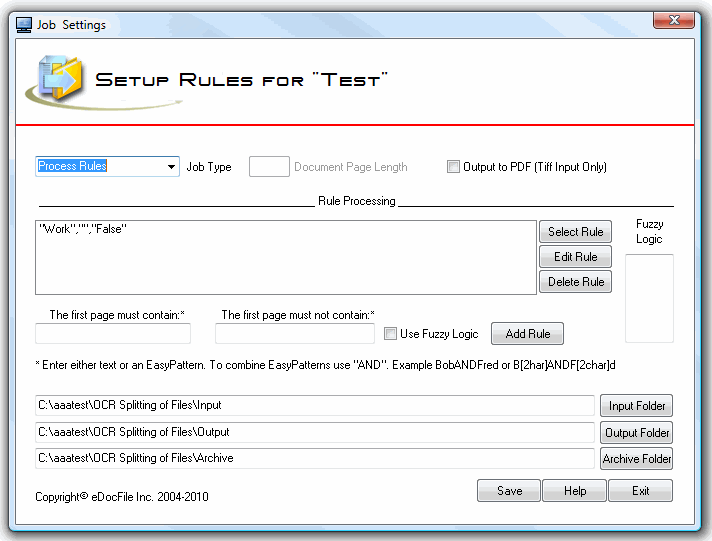
How it works:
To determine the beginning of the document the program utilizes the OCR engine in Microsoft Office Document Imaging to obtain the document's text or it will extract the text from a searchable PDF. Once extracted the text is searched to see if it contains text that matches a rule. The rule could be as simple as it has to contain a certain word or phrase. Or it could be it must contain, and must not contain certain words or phrases. To assist in correcting OCR errors the program utilizes fuzzy logic and EasyPatterns.



 Categories
Categories


